ORCID ID を作ってみた
何ヶ月も前から、試しに ORCID ID を取得しなければ、とは思ってはいたが、 目先の仕事以外のことはしたくない、という生来の面倒臭がりのために放置していた。 PlotNet のデータ入力に飽きたので気分転換に ORCID のサイトに アクセスしてみた。登録自体は簡単で、確かに5分もあれば済む。 認証メールは一応送られては来るが、 メール認証しなくても先に進むことができるので、逆にそれで 大丈夫かと心配になるくらいだ。 メール認証を放置すると後で取り消しになったりするのかしら。
ひとつ感心したのが、パスワード入力欄のヘルプに、パスワード文字列で 使用可能な記号文字をきちんと明記してあるところだ。
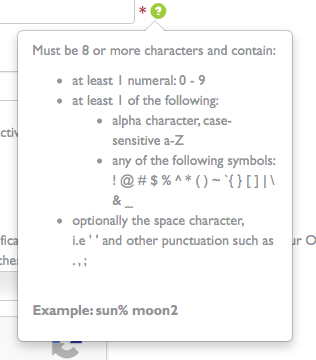
私は普段、パスワード用文字列を乱数生成するのに apg というツールを使っている。
mac:~$ apg -h
apg Automated Password Generator
Copyright (c) Adel I. Mirzazhanov
(snip)
mac:~$ apg -a 1
>~B"Av~qJ1
$xphcK~qO/
kbUX8Kp`Ke
\hX?,LQ$
nlZ#2'pQ6
z"~1TtF(M
apg は ‘” とか <> とかの記号を遠慮なく混ぜてきて、パスワードの強度としてはいいのだが、 これをそのまま入力フォームにコピーすると、時々、エラーを吐くサイトがあって、 面倒臭い。使用可能文字に制限があるなら先に書いておくべきであろう。 こちらとしては、なるべく強度の高い文字列を選んで使おうとしているのに、 それがエラーとなると、恩を仇で返されたような気分になるのである。
私の ID は 0000-0002-3987-2098 になった。
勤務先情報の入力などもあっと言う間に終わってしまい、拍子抜けしたので、 遊びで自分の姓を検索してみた。
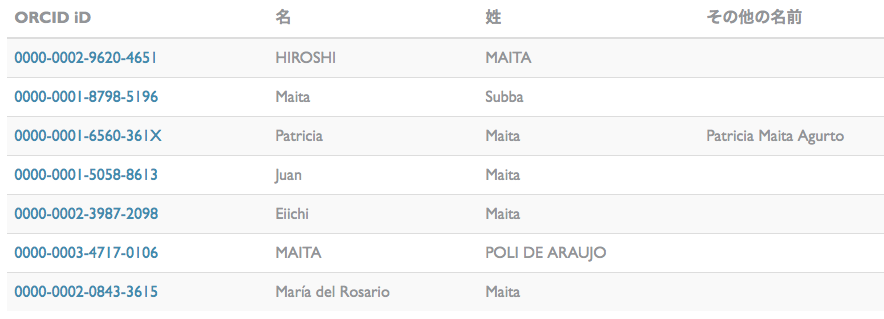
結果は 7件。大半がラテン系と思われる人名だが、中にひとり、「まいたひろし」という いかにも日本人っぽい名前の人物が居た。名前以外の情報は未入力か非表示にしているようで、 どこの誰だかは ORCID 上では判らない。
CiNii で検索すると、米田宏(バイオ系)と米田広(流体工学)という人物が出てきた。 「米田」を「よねだ」ではなく「まいた」と読ませる姓が存在することは前から知ってはいたが、 ふたりも出てくるとは思わなかった。 おそらくこのうちのどちらかが ORCID に登録したのであろう。どちらなのかは 情報不足で判らない。おそらく、私がそれを知る機会は無いだろう。
KNB にエチゼンクラゲ
ここしばらくの間ずっとデータ入力に掛かり切りで、世間の動向に無関心で過ごした。 今日あたり東京で IDF の会議があるはずだが、申し込みとかすっかり忘れていて、 まぁいいか別に俺は行かなくて、と思うことにした。
EML ソフトウェアがバージョンアップされてないか、と思い、 久しぶりに KNB のサイトに行ってみた。 数ヶ月前は、確か、証明書関係のエラーが出て接続できなかったような気がするが、 今日行ってみたところ、普通に表示された。直ったのか、記憶違いか。
ソフトウェアの新バージョンは無かったが、 データベースの中に日本のデータセットが3件あるのに気付いた。 漁業情報サービスセンターのエチゼンクラゲのデータのようで、 3件とも中身は同じようだが何故かメタデータは 3件登録されている。 よく解らない。
どういう経緯で登録されたのか。 メタデータの中に “Usage restricted to Global Jellies Working Group members.” と書いてあって、ググってみると NCEAS かどこかがクラゲのデータベースを作ってるらしく、 その関係で日本が取っている日本周辺のデータを提供したもののようだ。
しかしいつの間にか KNB のデータベースに DOI が導入されているね。 このクラゲデータセットにも DOI 付いてるし。 金があるところは色々出来ていいなぁ。
JDC の不具合
先週の JaLTER DB 講習会で発覚したのだが、 IE 11 では JDC のファイルアップロード機能が上手く動作しない。 同じ PC 上で Chrome で操作すると動作するので、OS ではなく ブラウザが原因なのだろう。
手元に IE 11 が動作する PC が無く、原因究明ができないため、 差し当たり他のブラウザを使用して頂きたい。
TR DCI 続報
JaLTER DB に格納されているデータセットの一部について、 そのメタデータをトムソンロイター社の Data Citation Index に提供するという件、 結局メタデータは ftp で送るということになり、6月に送信してあった。
その後、向こうでどのような作業が進んでいるのかまったく音沙汰が無かったのだが、 先日、TR DCI の “Master Data Repository List” を検索してみたら、 JaLTER DB が登録されているのを発見した。
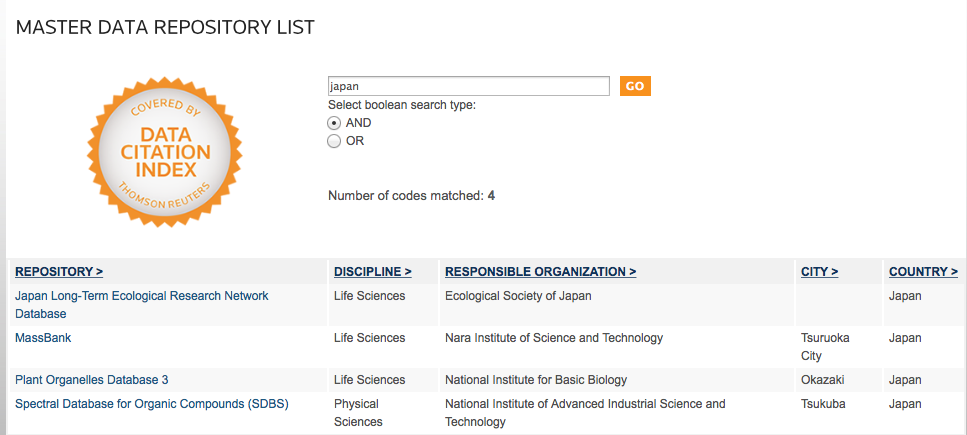
9月頭に調べた時には発見できず、9/14 に調べた時にはヒットしたので、 その間の約 2週間の間に登録されたようだ。6月にメタデータを送ってから 9月まで、一体何に時間が掛かっていたのか、よく解らないが、 ともかく向こうの作業が進んでいるようなので安心した。
本来なら DCI そのものを検索して、JaLTER DB のレコードが登録されているか どうか確かめたいのだが、以前に記述したように、NIES では DCI を契約していない ので私が直接確かめる方法が無い。伝手を辿ってみるか…
しかしそれにしても、JaLTER DB の Responsible Organization として 日本生態学会が記載されているのはどうしたものか。向こうとしては、 JaLTER のような、永続性に不安がある組織よりも、学会のような 社会的・財政的に確立された組織の方が好ましい、ということなのだろうか。 この点は後で検討した方がいいかも知れない。
FileReader 追記
JDC に投入したデータを遡って調査したところ、壊れたファイルが見つかったので 再投入した。
調査の過程で解ったことは、2014年4月まではファイル破損がなく、 2015年4月から破損が生じていることである。このことから、 2014年4月後半に端末の MacBook を買い替えたことがエラー顕在化の 原因と推定される。
以前に使用していた MacBook は 2009年に購入したもので、性格が貧乏性のため 2014年まで使っていた。OS も Leopard のまま、アップグレードせず。 おそらく、Leopard の Safari には FileAPI が実装されていなかったのだろう。 ネットで拾った JavaScript コードは、 FileReader が実装されていればそれを使い、 実装されていなければファイルを直接読む、というようなロジックが組まれていたので、 前の MacBook で開発している時には FileReader.readAsBinaryString() が 実行されていなかったのだと思われる。そのため開発中ずっとこのバグに 気がつかなかった、ということなのだろう。
盲点だった。古い環境を使い続けるのも考えものだな。
これで少なくとも、私が JDC 開発中にバグに気付かなかった原因は解った。 しかし他の人々が FileReader.readAsBinaryString() の挙動を誤解していた (している?)原因はやはり不明である。
FileReader.readAsBinaryString は Binary を返さない
JDC にバグが見つかった。zip ファイルをサーバにアップロードすると、 ファイルが壊れるというものだ。テスト用インスタンスを立ち上げて 挙動を見てみると、サーバ側ではなくクライアント側でファイルが壊されているようだった。 具体的には、ファイルサイズが何故か 1.5 倍に増加しており、しかも、データが ランダムなバイト列ではなく UTF-8 にエンコードされているのであった。
ファイルのアップロードにはネットで拾ったパプリックドメインの JavaScript コードを 利用していて、これがファイルの読み込みとサーバへの送信を実行している。 読み込みから送信までの間に何かが起こっているのだろう、とはすぐに見当がついた。 処理を追いかけて調べた結果、FileReader.readAsBinaryString() が読み込んだ ファイル内容を破壊していることがわかった。 これを FileReader.readAsArrayBuffer() に変更することでバグ自体は 修正できたのだが、これについて調べた結果がやや興味深かったので記録しておく。
さてこの FileReader.readAsBinaryString() 、字面からは、バイナリファイルを 読み込んで中身のバイナリデータをメモリ上に保持する函数であるかのように見える。 ネット上の記事でもそのように解説されているものが多いようだ。 たとえば これ とか これ とか これ とか。
ところが、実はそうではない。 FileReader.readAsBinaryString() は仕様上 DOMString オブジェクトにデータを 格納することになっており、そして DOMString は UTF-8 しか受け付けない。 だから、少なくとも仕様上は、 FileReader.readAsBinaryString() は ランダムなバイト列を読み込むことはできないのである。 ( 参考 )
そのため、たとえば Safari のエンジンである WebKit ではどうなっているかと言うと、
Source/WebCore/fileapi/FileReaderLoader.cpp:295
switch (m_readType) {
case ReadAsArrayBuffer:
// No conversion is needed.
break;
case ReadAsBinaryString:
m_stringResult = String(static_cast<const char*>(m_rawData->data()), m_bytesLoaded);
break;
ReadAsArrayBuffer ではデータに何も加工しないのに対して ReadAsBinaryString では String クラスに渡す。この String には コンストラクタが数種類定義されているが、この場合に呼ばれるのは、
Source/WTF/wtf/text/WTFString.h:84-
class String {
..snip..
// Construct a string with latin1 data.
WTF_EXPORT_STRING_API String(const LChar* characters, unsigned length);
WTF_EXPORT_STRING_API String(const char* characters, unsigned length);
の下の方である。コメントに書かれているように、入力データを latin1 として 強制的に解釈する。そして target.result に結果を格納する際に UTF-8 に変換する のであろう。
実際、サーバに送信された壊れたデータを取り出して、元のファイルと比較してみると、
iconv -f L1 -t UTF-8
と変換した場合にファイルサイズも内容も一致した。
この FileReader.readAsBinaryString() 、実は 2012年に W3C の仕様から 削除されている。 2011年の仕様 では、 代わりに readAsArrayBuffer() を使うようにと書かれている。 その理由は、 readAsBinaryString() が、readAsBinaryString という名称でありながら DOMString の制限のためにバイナリを返せないという中途半端な函数だったからだろう。
それにしてもよく解らないことがある。
まず、多くの人が、readAsBinaryString() はバイナリファイルの内容をそのまま 保持する函数だと思っていたことである。 ざっとググった限りでは、そうではないと書いてある日本語ページは ここ くらいである。
もしかしたら、以前のブラウザの実装は、W3Cの仕様に反して、内容を加工しない ようになっていたのかも知れない。何しろわたしも JDC の開発中にこのことに 気がつかなかった。しかし WebKit のリポジトリから 2011年頭頃のコードを 取り出してみたが、今現在と変わらないように見える。 他の webエンジンではどうなのだろうか。
FormAlchemy のカスタマイズ
FormAlchemy には PostgreSQL の範囲型や配列に対応する renderer が 用意されていない。しかしコードを読んだらカスタマイズはそれほど 難しくはなさそうだったので書いてみた。
要点は、 formalchemy.fields.FieldRenderer をベースにして render(), render_readonly(), deserialize() 等をオーバーライドする。 フォーム出力用に formalchemy.helpers.text_field() というヘルパー函数が 用意されているため、これを利用すれば手間が省ける。 deserialize() はフォームの入力内容をパースする時に呼ばれるメソッドで、 入力内容を解釈して適切な Python オブジェクトに変換する機能を持たせる。
init4range と array 用のコードは以下のようになる。 これを forms.py に追加する。
from formalchemy import FieldSet
from formalchemy.helpers import text_field
from sqlalchemy.dialects.postgresql import INT4RANGE, ARRAY
from formalchemy.fields import FieldRenderer
from psycopg2.extras import NumericRange
class Int4RangeRenderer(FieldRenderer):
def _range_string(self):
# self.value は u"NumericRange(115, 889, '[)')" という文字列になっている
# self.raw_value に NumericRange インスタンスがあるのでそれを利用
# PostgreSQL 内には "[lower, upper+1)" という形式で格納されるようだが
# 解り難いので "[lower, upper]" という形式で入出力する
if isinstance(self.raw_value, NumericRange):
value = "[{},{}]".format(self.raw_value.lower, self.raw_value.upper-1)
else:
value = ""
return value
def render(self, **kwargs):
return text_field(self.name, value=self._range_string(), **kwargs)
def render_readonly(self, **kwargs):
return self._range_string()
FieldSet.default_renderers[INT4RANGE] = Int4RangeRenderer
class ArrayRenderer(FieldRenderer):
def render(self, **kwargs):
value = " ".join(self.raw_value)
return text_field(self.name, value=value, **kwargs)
def deserialize(self):
# スペース区切りの文字列として受け取る
data = self.params.getone(self.name)
data = data.split()
return data
FieldSet.default_renderers[ARRAY] = ArrayRenderer
FormAlchemy の設計では配列型の中身のデータ型に応じて default_renderer を切り替えるようにはできないので、上記コードでは 配列型を一緒くたに扱っている。
Pyraid + GeoAlchemy2 + GeoFormAlchemy2 (4)
(承前)
次に、GeoAlchemy2 を使ってジオメトリデータを PostGIS に投入する方法を確認する。 簡単のため、Pyramid + GeoFormAlchemy2 は使用せずにロジックだけ追う。
モデルは以下とする。
class Plot(Base):
__tablename__ = 'plots'
id = Column(Integer, primary_key=True)
name = Column(Text)
geom = Column(Geometry('geometry', 4612))
作成するジオメトリは、複数の POINT を含むコレクションで、 以下をサンプルデータとする。
dat = [ [6,8], [8,1], [9,44] ]
ジオメトリのオブジェクトは shapely のものを利用する。
from shapely.geometry.point import Point
from shapely.geometry.collection import GeometryCollection
points = []
for i in dat:
points.append(Point(i))
gc = GeometryCollection(points)
この時点で、例えば gc.to_wkt() とすると
GEOMETRYCOLLECTION (POINT (6.0000000000000000 8.0000000000000000), POINT (8.0000000000000000 1.0000000000000000), POINT (9.0000000000000000 44.0000000000000000))
が得られ、PostGIS に投入可能のように見えるが、残念ながらそうではなく、 SRID が指定されていない、とエラーが出る。
そこで、 GeoAlchemy2 の from_shape() を使用する。これは shapely オブジェクトを GeoAlchemy2 のオブジェクトに変換する函数だが、 SRID 情報を付加することができる。
from geoalchemy2.shape import from_shape
geo = from_shape(gc, srid=4612)
これでジオメトリオブジェクトが作成できたので、Plot インスタンスを生成して PostGIS に投入する。
plot = Plot()
plot.name = "test1"
plot.geom = geo
session.add(plot)
session.commit()
サンプルコードの完全版は以下の通り。
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy import Column, Integer, Text
from geoalchemy2 import Geometry
from geoalchemy2.shape import from_shape
from shapely.geometry.point import Point
from shapely.geometry.collection import GeometryCollection
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
db_url = "postgresql://gis:gis@localhost/gistest"
dat = [ [6,8], [8,1], [9,44] ]
db_engine = create_engine(db_url)
DBSession = sessionmaker(bind=db_engine)
session = DBSession()
class Plot(Base):
__tablename__ = 'plots'
id = Column(Integer, primary_key=True)
name = Column(Text)
geom = Column(Geometry('geometry', 4612))
points = []
for i in dat:
points.append(Point(i))
gc = GeometryCollection(points)
geo = from_shape(gc, srid=4612)
plot = Plot()
plot.name = "test1"
plot.geom = geo
session.add(plot)
session.commit()
これで、GeoAlchemy2 の使い方はだいたい解った。
Pyraid + GeoAlchemy2 + GeoFormAlchemy2 (3)
(承前)
Python コード内で GeoAlchemy2 を使う
サンプルとして下図のようなデータを作成した。
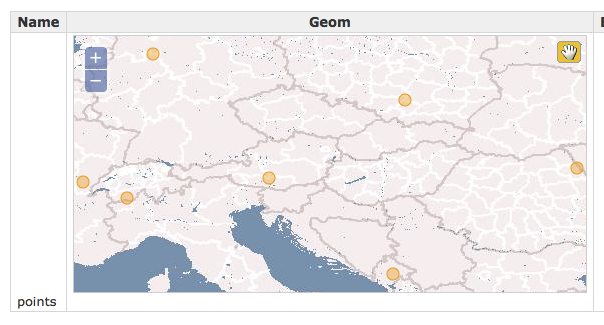
PostGIS 上で見ると、
gistest=> select * from plots;
id | name | geom
----+--------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 | points | 010700002004120000070000000101000000F2FFFFFF23932140DDFFFFFFF9364A400101000000E4FFFFFF47941E40DDFFFFFFF90C47400101000000E4FFFFFF47D81640DDFFFFFFF96647400101000000BAFFFFFF23C52B40DDFFFFFF797D47400101000000DDFFFFFF916B3B40DDFFFFFFB9B547400101000000DDFFFFFF91DC3340DDFFFFFF393449400101000000DDFFFFFF91553340DDFFFFFF79614540
(1 行)
一方、Pyramid 上でビュー函数を定義し、そこにデバッグ用 print 文を仕込んでみる。
@view_config(route_name='item', renderer='templates/plot.pt')
def item_view(request):
item_id = request.matchdict['id']
item = DBSession.query(Plot).filter(Plot.id == item_id).first()
print item.geom
すると、pserve を実行したコンソール上に同じ文字列が出力される。
0107000000070000000101000000f2ffffff23932140ddfffffff9364a400101000000e4ffffff47941e40ddfffffff90c47400101000000e4ffffff47d81640ddfffffff96647400101000000baffffff23c52b40ddffffff797d47400101000000ddffffff916b3b40ddffffffb9b547400101000000ddffffff91dc3340ddffffff393449400101000000ddffffff91553340ddffffff79614540
これは OpenGIS の WKB (Well-Known Binary) フォーマットのデータを hex 表現したもので、PostGIS に格納されている元々のデータは バイナリである(と思われる)。 item.geom オブジェクトは geoalchemy2.elements.WKBElement クラスの インスタンスで、このクラスは data と desc の属性を持つ。 data 属性はバイナリ表現のデータを保持し、desc は data の内容を hex 化して 返す、@property でデコレーションされたメソッドである。
WKB を WKT (Well-Known Text) 形式に変換するには主にふたつの方法がある。 PostGIS サーバに変換させる方法と、ローカルマシンで処理する方法である。
PostGIS サーバに変換させるには、geom カラムに ST_AsText() 函数を適用すれば良い。 ビュー函数のデバッグ文を以下のように変更する。
print DBSession.scalar(item.geom.ST_AsText())
すると出力は、
GEOMETRYCOLLECTION(POINT(8.7873840332031 52.429504394531),POINT(7.6448059082031 46.101379394531),POINT(5.7112121582031 46.804504394531),POINT(13.885040283203 46.980285644531),POINT(27.420196533203 47.419738769531),POINT(19.861602783203 50.408020019531),POINT(19.334259033203 42.761535644531))
コレクションの中身を分割させるには ST_Dump() 函数を使う。
a = DBSession.execute(item.geom.ST_Dump().geom.ST_AsText())
for i in a.fetchall():
print i
出力は、
(u'POINT(8.7873840332031 52.429504394531)',)
(u'POINT(7.6448059082031 46.101379394531)',)
(u'POINT(5.7112121582031 46.804504394531)',)
(u'POINT(13.885040283203 46.980285644531)',)
(u'POINT(27.420196533203 47.419738769531)',)
(u'POINT(19.861602783203 50.408020019531)',)
(u'POINT(19.334259033203 42.761535644531)',)
各行がタプルになっている点に注意が必要だ。
ローカルマシンに変換させる場合は geoalchemy2.shape.to_shape() を使う。 ビュー函数を修正してアプリケーション再起動。
from geoalchemy2.shape import to_shape
@view_config(route_name='item', renderer='templates/plot.pt')
def item_view(request):
item_id = request.matchdict['id']
item = DBSession.query(Plot).filter(Plot.id == item_id).first()
print to_shape(item.geom)
コンソール出力は以下のようになる。
GEOMETRYCOLLECTION (POINT (8.7873840332031 52.429504394531), POINT (7.6448059082031 46.101379394531), POINT (5.7112121582031 46.804504394531), POINT (13.885040283203 46.980285644531), POINT (27.420196533203 47.419738769531), POINT (19.861602783203 50.408020019531), POINT (19.334259033203 42.761535644531))
geoalchemy2.shape.to_shape() は shapely というパッケージを利用しており、 shapely は OS の libgeos を呼び出しているようだ。
to_shape() の返り値はオブジェクトで、この場合は <class ‘shapely.geometry.collection.GeometryCollection’> になる。このクラスはリストとして動作するのでスライス操作で要素を取り出すことが できる。 個々の要素は、この場合は <class ‘shapely.geometry.point.Point’> で、 POINT データの内容を更に操作することができる。たとえば X座標値だけを取り出すには
for i in shape.to_shape(item.geom):
print i.x
などとすれば良い。
Python コードとの相性は geoalchemy2.shape の方が良さそうだ。 ただ、PostGIS と libgeos がトポロジー計算などでまったく同じ精度の 計算を行うのかどうかは確かめないといけない。
Pyramid + GeoAlchemy2 + GeoFormAlchemy2 (2)
(承前)
ジオメトリの種類を変える
models.py の point を multipoint に変えてみる。
class Plot(Base):
__tablename__ = 'plots'
id = Column(Integer, primary_key=True)
name = Column(Text)
geom_point = Column(Geometry('multipoint', 4612))
テーブルを作り直してアプリケーション再起動。 すると下図のように、OpenLayers インターフェイス上で 多点指定ができるようになった。
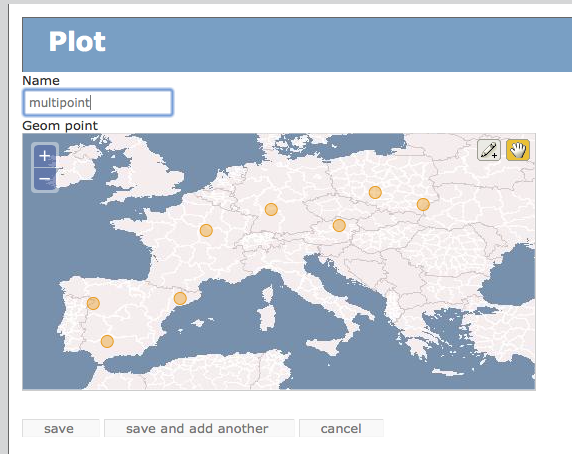
linestring と multilinestring、 polygon と multipolygon も同様の関係になる。
さて汎用の geometry を指定した場合にどうなるか、だが、
geom = Column(Geometry('geometry', 4612))
point, linestring, polygon を自由に指定できる。
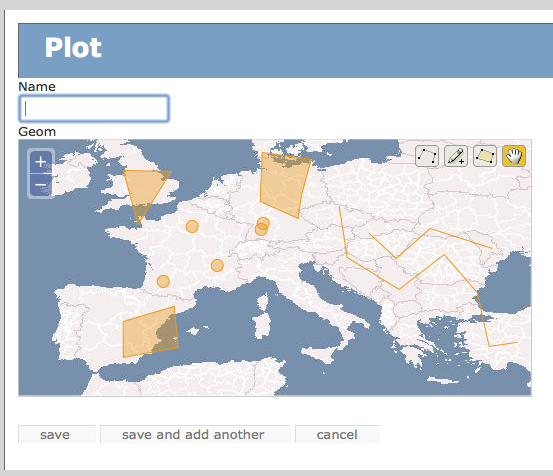
geometry は geometrycollection でも良いようだ。
geom = Column(Geometry('geometrycollection', 4612))
複数カラム
ひとつのテーブルに複数のジオメトリカラムを作成した場合にどうなるか、 見てみる。models.py を以下のように修正してテーブルを作り直す。
class Plot(Base):
__tablename__ = 'plots'
id = Column(Integer, primary_key=True)
name = Column(Text)
geom_geometry = Column(Geometry('geometry', 4612))
geom_point = Column(Geometry('multipoint', 4612))
geom_line = Column(Geometry('multilinestring', 4612))
geom_polygon = Column(Geometry('multipolygon', 4612))
アプリケーションを再起動すると下図のようになる。 注意するべきは、2段目、3段目に表示されるべきデータが 4段目に表示されているところである。
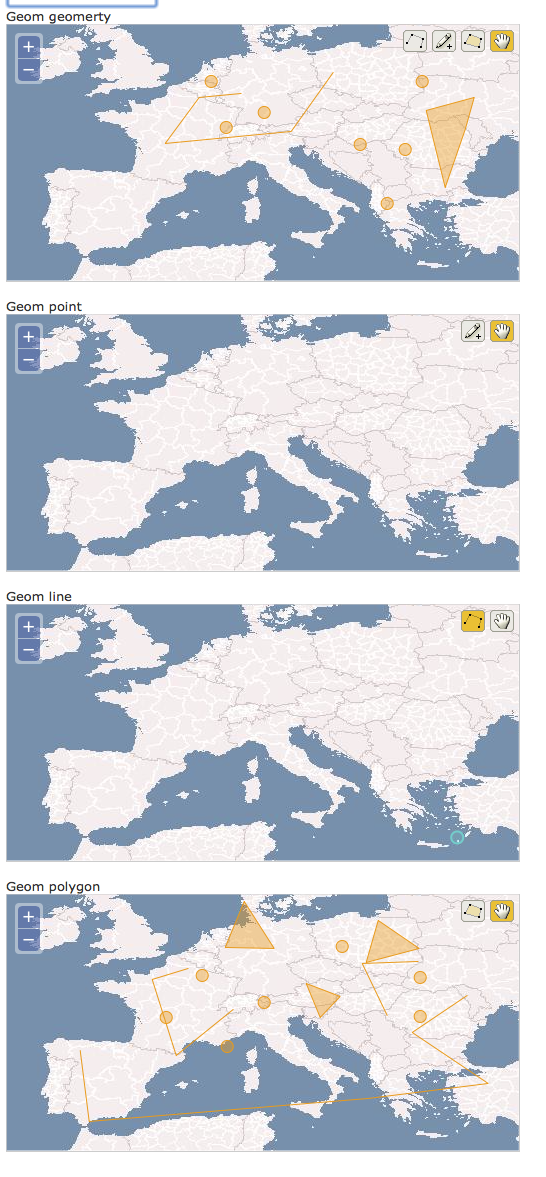
これは、GeoFormAlchemy の renderer が、OpenLayers 用に、 まったく同一の JavaScript コードを 4回出力しているからだと思われる。 OpenLayers インスタンスへの参照を保持する変数名を使い回すことになるため、 4個目のインスタンスだけが変数に格納され、 1-3個目のインスタンスは、メモリ上には存在するが JavaScpript コードからはアクセスできないようになる。 結果的に、すべての入力内容が 4個目のインスタンスに渡されることになる、 ということなのだろう。 ただ、上図では 1個目のインスタンスだけは正常に動作しているようで、 それが何故なのか、この理屈ではよく解らない。
ちなみにこのまま save しようとするとエラーが出る。4個目のカラムは multipolygon 用であり、point や linestring を格納しようとするとエラーが 出るのである。
GeoFormAlchemy のこの挙動をバグと捉えるかどうかは悩ましいところである。 何故なら、OpenGIS では基本的に、ひとつのテーブルに対して ジオメトリカラムはひとつであることを措定しているからだ。 GIS は地物を扱う。地物には様々な属性が附属しており、ジオメトリも 属性のひとつである。ひとつの地物が複数のジオメトリを持つことはありえない。 何故なら地物はひとまとまりの物理的実体であり、従ってひとまとまりの ジオメトリしか持ち得ないからである。
よって、そもそも上記の models.py のような、ジオメトリタイプごとに カラムを分けるようなテーブル設計は OpenGIS の流儀から外れている、 ということだ。複雑なジオメトリデータを格納する場合は geometrycollection を 使うべきである。
なお、私は昨日まで PostGIS 等を使用したことがなく、OpenGIS に関する 上記の記述も、ついさっき小一時間調べただけに過ぎない。 私の理解が間違っているかも知れないので直ちに真に受けてはいけない。
(続く)